








开云体育 
开云APP下载一键部署DeepSeek-V3、DpSk-R1模型
 2025-11-19
2025-11-19 浏览次数:
次
浏览次数:
次 返回列表
返回列表开云体育[永久网址:363050.com]成立于2022年在中国,是华人市场最大的线上娱乐服务供应商而且是亚洲最大的在线娱乐博彩公司之一。包括开云、开云棋牌、开云彩票、开云电竞、开云电子、全球各地赛事、动画直播、视频直播等服务。开云体育,开云体育官方,开云app下载,开云体育靠谱吗,开云官网,欢迎注册体验!系列模型,无需处理底层计算环境配置、模型加载和推理优化等基础设施管理工作。最终获得一个兼容标准
Model Gallery:作为模型的分发与部署入口,提供了预置的DeepSeek系列模型及相应的部署配置。
模型在线服务 (EAS):承载模型部署与推理的核心服务。它负责自动化地管理底层计算资源(如GPU),并根据配置启动模型服务实例。
BladeLLM:自研的高性能推理框架,在特定场景下可提供更优的推理性能。
API网关:EAS将部署好的模型服务通过一个安全的API网关暴露出来,提供服务访问地址(Endpoint)和认证令牌(Token)。
优先推荐SGLang:在提供高性能的同时,完全兼容OpenAI API标准,适配主流应用生态,在多数场景下支持的最大上下文长度优于vLLM。
特定场景使用BladeLLM:仅在追求更高推理性能,且能接受API与OpenAI标准存在差异(例如,不支持通过client.models.list(),max_tokens参数有默认截断行为)时,才选用阿里云 PAI 自研的高性能推理框架BladeLLM。
模型的选择决定了所需的计算资源和部署成本。DeepSeek模型分为“满血版”和“蒸馏版”,其资源需求差异巨大。
开发测试:推荐使用蒸馏版模型,如DeepSeek-R1-Distill-Qwen-7B。此类模型资源占用小(通常为单张24GB显存的GPU),部署快,成本低,适合快速验证功能。
生产环境:根据效果和成本综合评估。DeepSeek-R1-Distill-Qwen-32B在效果和成本之间取得了较好的平衡。如需更强的模型效果,可选择满血版,但这需要多卡高端GPU(如8卡96GB显存的GPU),成本会显著增加。
下表列出了不同模型版本所需的最低配置,以及使用不同机型和推理引擎时支持的最大Token数。
GP7V机型:ml.gp7vf.16.40xlarge为公共资源,仅可竞价使用。当Nvidia GPU资源紧张时,可切换至华北6(乌兰察布)寻找GP7V资源,部署时请务必配置VPC。
分布式部署依赖高速网络,故必须使用PAI灵骏智算资源(提供高性能、高弹性异构算力服务)且部署时务必配置VPC。使用灵骏智算资源请切换地域至华北6(乌兰察布)。
登录PAI控制台,在顶部左上角选择目标地域,从左侧导航栏进入工作空间列表,并选择目标工作空间。
使用公共资源部署,服务进入运行中状态即开始按时长计费,即使无调用。测试后请及时停止服务。
若选择资源配额,请注意根据机型选择对应的推理引擎和部署模板。如使用GP7V机型,推理引擎可选择SGLang,部署模板可选择单机-GP7V机型。

对于大型模型(如DeepSeek-R1满血版),模型加载过程可能需要20-30分钟。
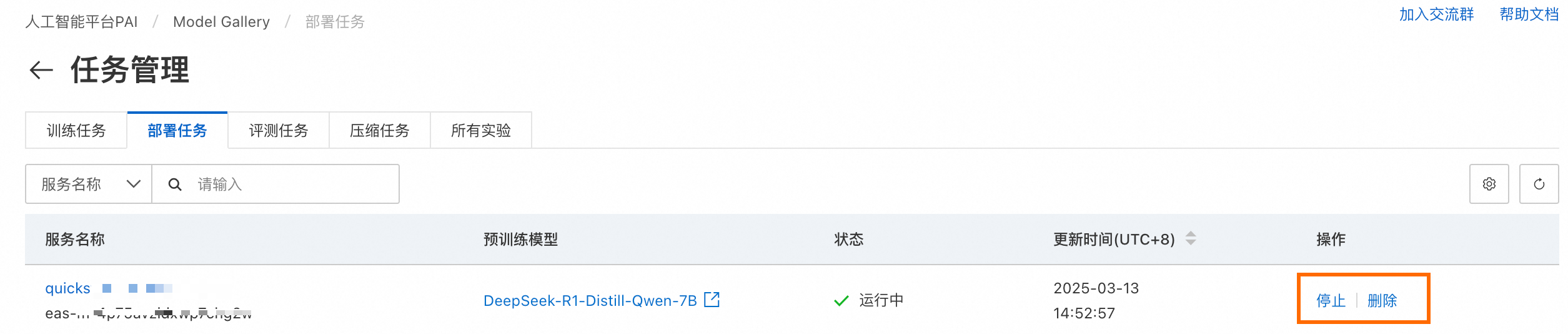
部署任务的状态可在Model Gallery任务管理部署任务页面查看。单击服务名称可进入服务详情页。还可以通过右上角的更多信息,跳转到PAI-EAS的模型服务详情页,获取更多信息。
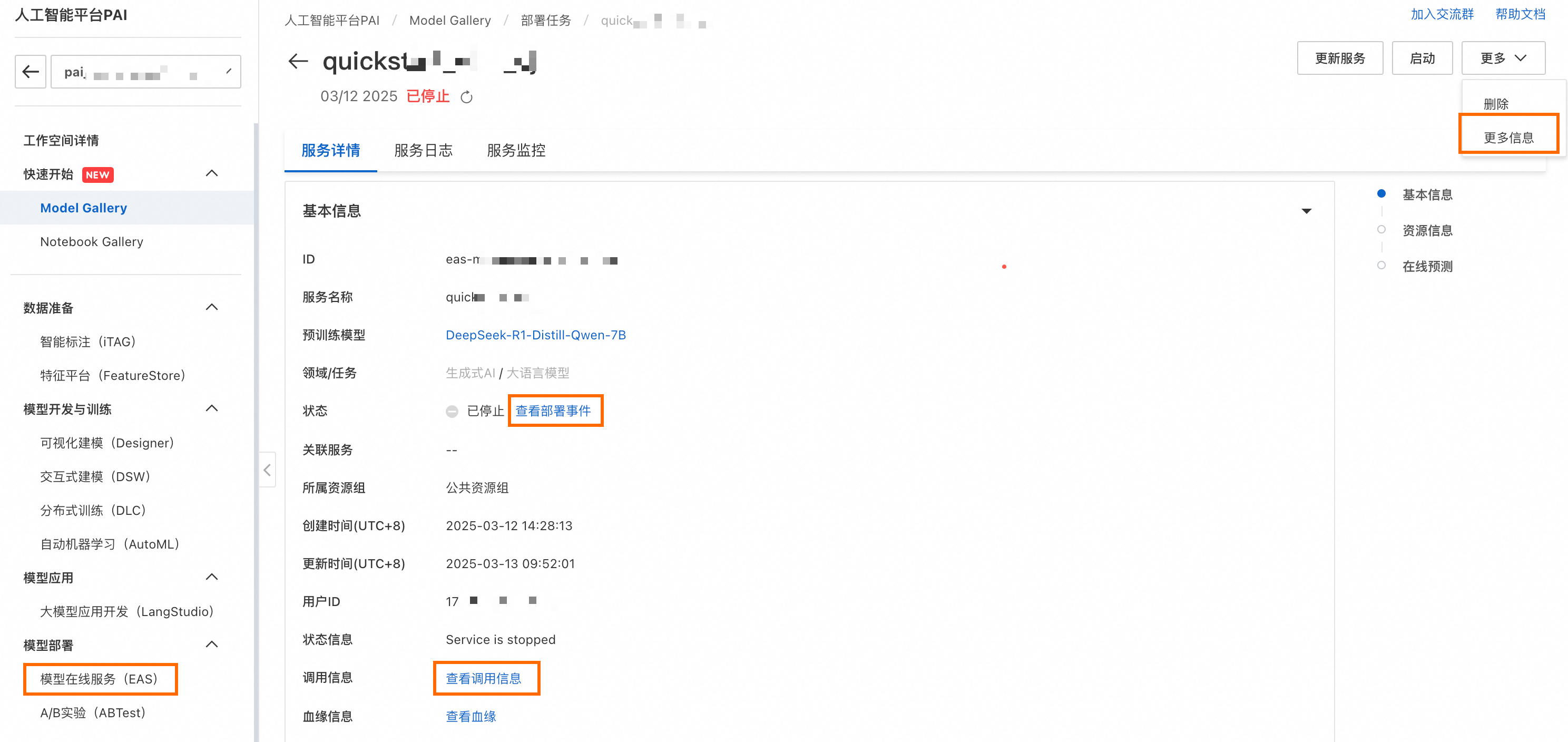
在Model Gallery任务管理部署任务中单击已部署的服务名称,在在线测试模块中找到EAS在线调试的入口。
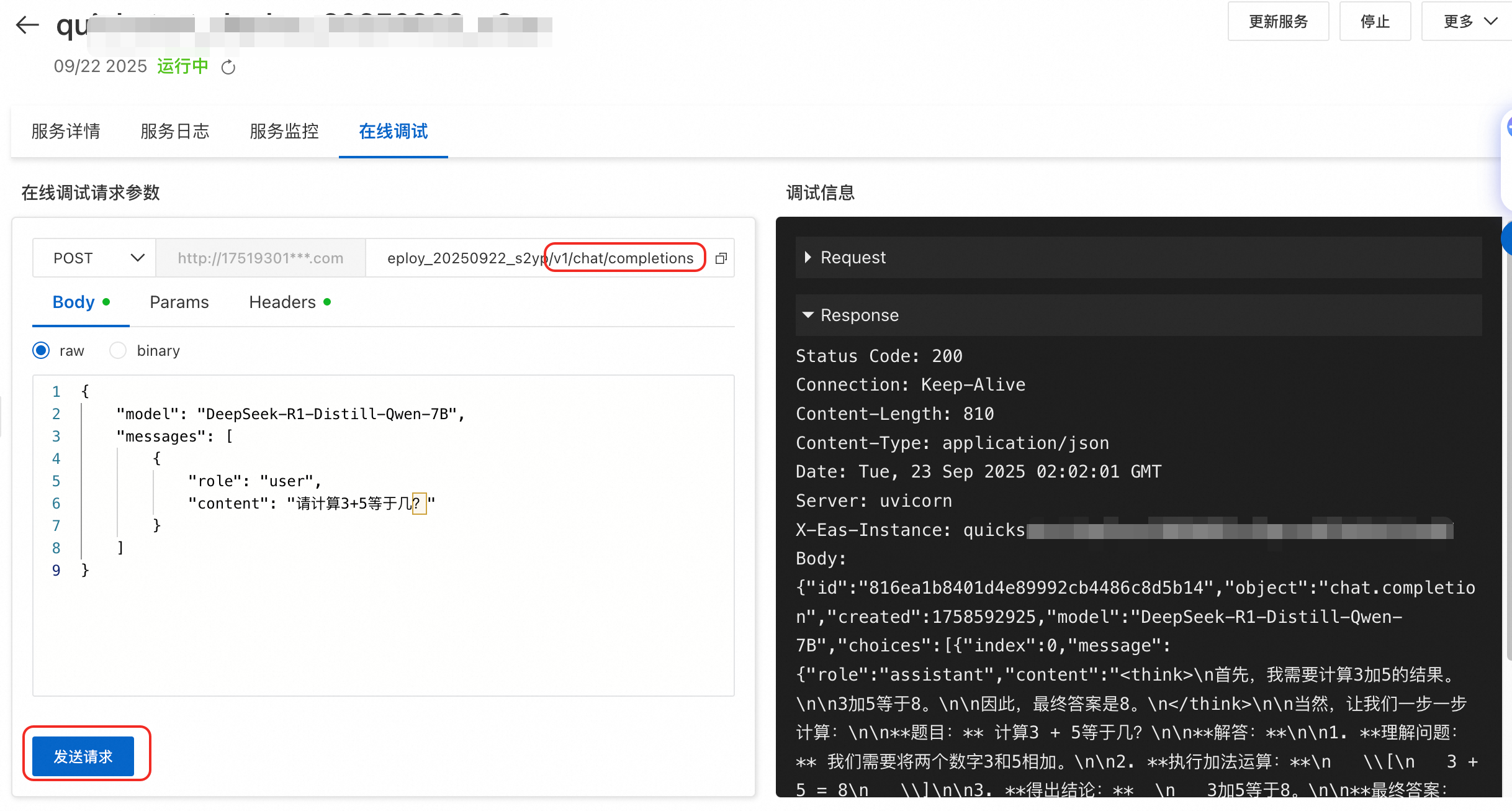
针对数学类问题,建议在 prompt 中包含“请逐步推理,并将最终答案放在\boxed{}中。”
使用BladeLLM加速部署方式,如果不指定max_tokens参数,默认会按照max_tokens=16进行截断。建议您根据实际需要调整请求参数max_tokens。
在Model Gallery任务管理部署任务中单击已部署的服务名称,进入服务详情页。
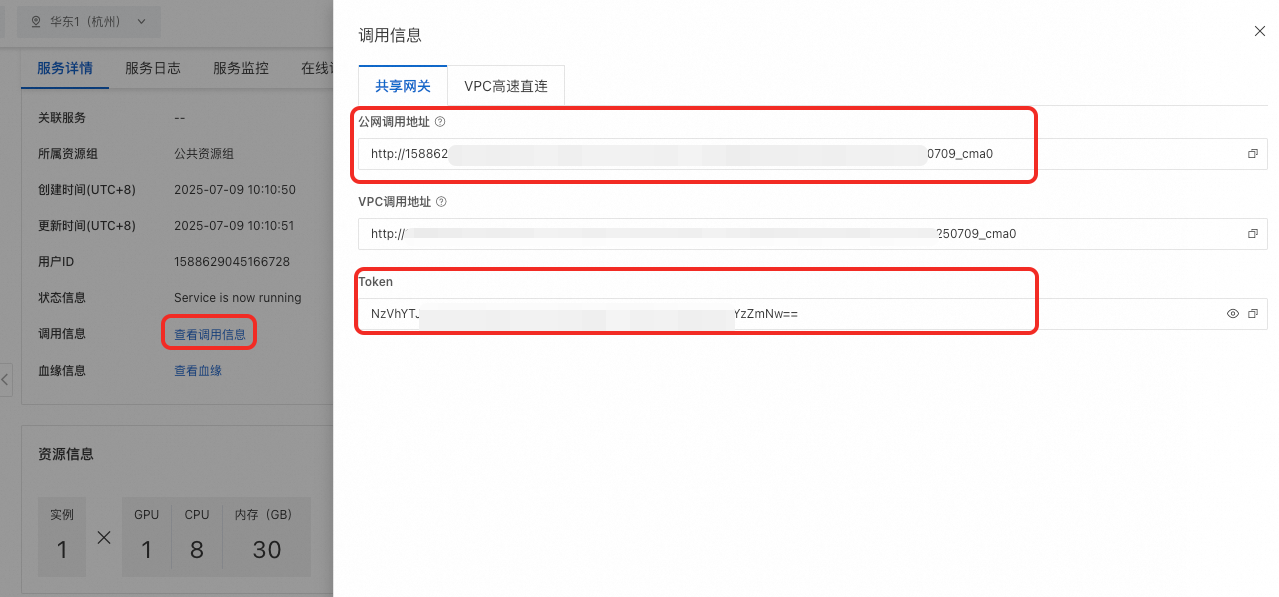
BladeLLM加速部署不支持使用client.models.list()方式获取模型列表,您可以直接指定model的值为以兼容使用。
不同的模型以及不同的部署框架,在使用推理服务时也会存在区别。您可以在Model Gallery的模型介绍页查看更多API调用方式的详细说明。
Gradio是一个基于Python的用户友好的界面库,能快速创建机器学习模型的交互式界面。请参考以下步骤,在本地运行Gradio WebUI。
下载代码:根据部署时选择的推理引擎,下载对应代码。如网络环境可稳定访问GitHub,请使用GitHub链接,否则请使用OSS链接。
启动成功后,会输出一个本地URL(通常是),在浏览器中打开该URL进行访问。
使用公共资源部署的实例,创建成功后按实例运行时长计费,不满1小时按具体分钟数折算计费;为避免产生更多资源消耗,在完成使用后,应停止或删除实例。
使用公共资源部署的服务,从创建成功(状态为“运行中”)到停止或删除为止,按分钟计费,账单按小时结算。即使服务空闲,计费依然持续。停止服务即可停止计费。
使用试用资源:若首次使用EAS,可前往阿里云试用中心领取PAI-EAS试用资源。领取成功后,可以选择部署最低配置为 A10 的模型(如DeepSeek-R1-Distill-Qwen-7B),并在部署时修改资源规格为试用活动中的机型。
竞价使用资源:对于非生产任务,可在部署时开启竞价模式,但注意需满足一定条件才能竞价成功,且有资源不稳定的风险。
长期使用优惠:对于长期运行的生产服务,可通过购买节省计划或预付费资源来降低成本。
BladeLLM输出截断:使用BladeLLM引擎时,若API请求中未指定max_tokens,输出将被截断为16个token,导致功能不符合预期。
资源库存:部署大型模型(特别是满血版)时,特定地域的高端GPU资源可能库存紧张,导致部署失败或长时间等待。可尝试切换到其他地域。
您可以耐心等待观察一段时间,如果服务仍长时间无法正常启动运行,建议尝试以下步骤:
进入任务管理-部署任务,查看部署任务详情页。在页面右上角单击更多更多信息,跳转到PAI-EAS的模型服务详情,查看服务实例状态。
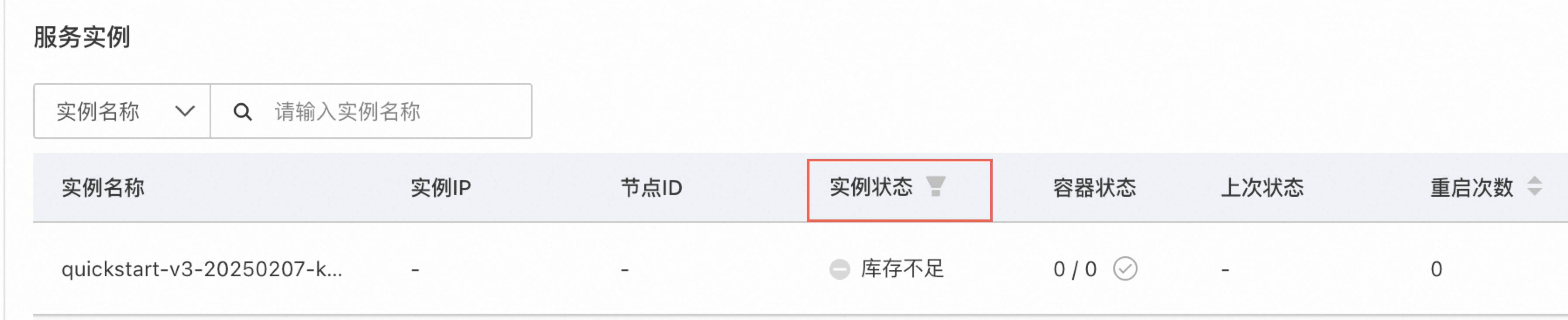
对于DeepSeek-R1、DeepSeek-V3这样的超大参数量模型,需要8卡GPU才能启动服务(资源库存较紧张),您可以选择部署DeepSeek-R1-Distill-Qwen-7B等蒸馏小模型(资源库存较富裕)。
请检查调用的URL是否加上了OpenAI的API后缀,例如v1/chat/completions。详情可以参考模型主页调用方式介绍。
如果是vLLM加速部署,检查对话接口的请求体中model参数是否填写了正确的模型名称。可以通过v1/models获取模型名称。
部署使用的默认网关请求超时时间是180秒,如果需要延长超时时间,可以配置专属网关,并提交工单调整专属网关的请求超时时间,最大可以调整到600秒。
“联网搜索”功能并不是仅通过直接部署一个模型服务就能实现的,而是需要基于该模型服务自行构建一个AI应用(Agent)来完成。
通过PAI的大模型应用开发平台LangStudio,可以构建一个联网搜索的AI应用,详情请参考基于LangStudio&阿里云信息查询服务搭建DeepSeek联网搜索应用流。
如果部署DeepSeek-R1模型,针对模型有时会跳过思考过程的情况,可采用DeepSeek更新的强制思考的chat模板。使用方式:
字段,加上--chat-template /model_dir/template_force_thinking.jinja(可以加在--served-model-name DeepSeek-R1之后)。
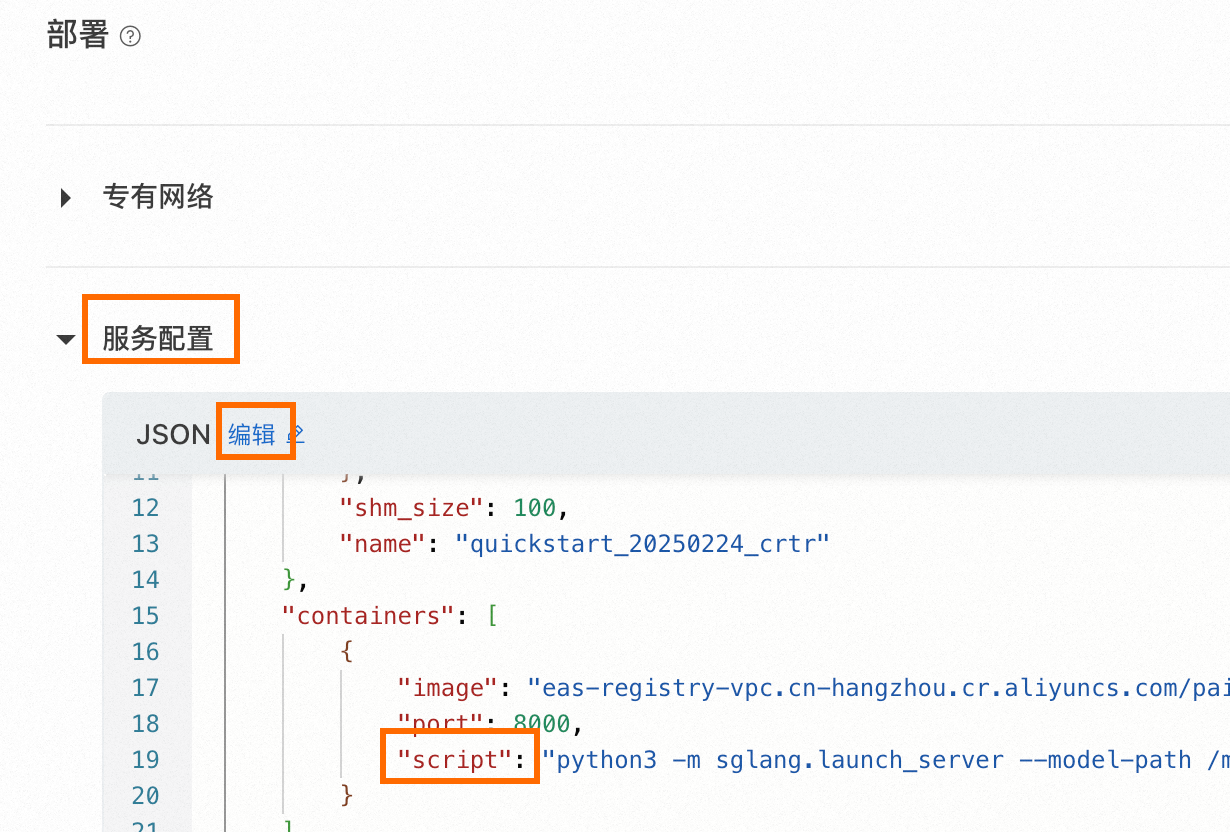
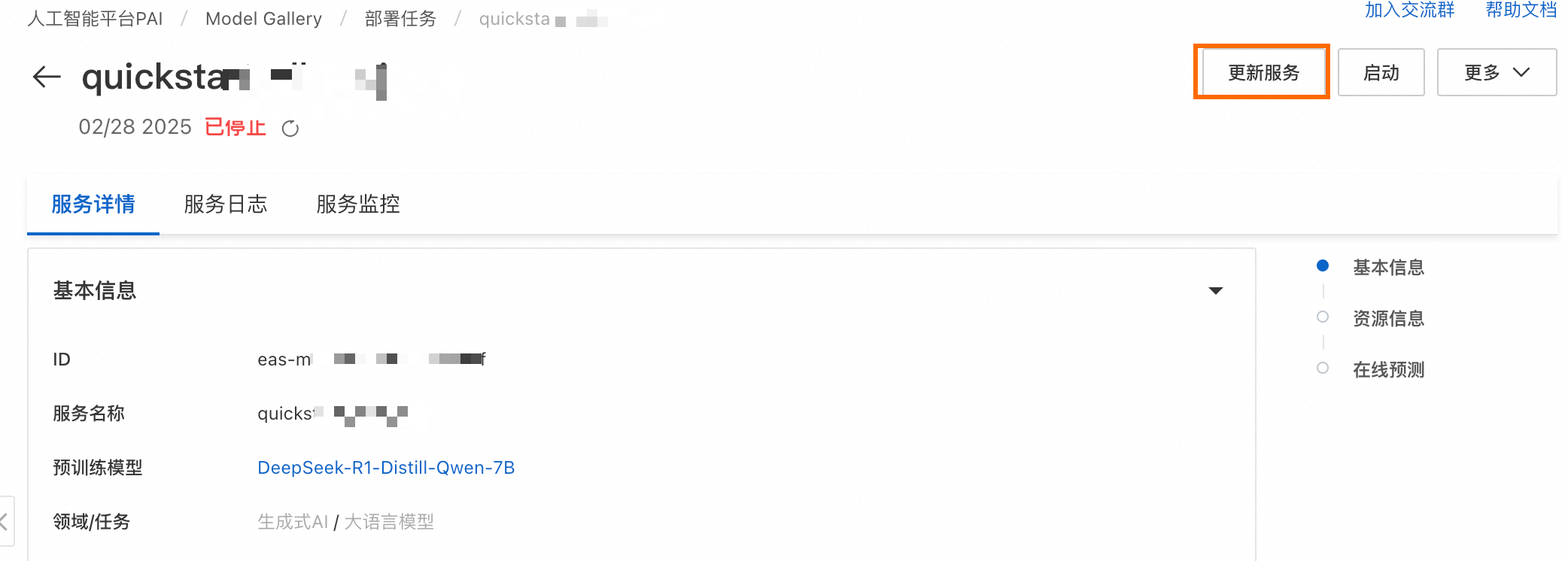
如果是已经部署的服务,在Model Gallery任务管理部署任务中单击已部署的服务名称,在详情页面右上角单击更新服务,即可进入上述页面。
模型服务本身不会保存历史对话信息,需要客户端保存历史对话,再添加到模型调用的请求中。以SGLang部署的服务,示例如下。
