








开云体育 
开云体育官方梁文锋的DeepSeek让AI界惊艳40岁的他引领中国科技发展
 2025-12-15
2025-12-15 浏览次数:
次
浏览次数:
次 返回列表
返回列表开云体育[永久网址:363050.com]成立于2022年在中国,是华人市场最大的线上娱乐服务供应商而且是亚洲最大的在线娱乐博彩公司之一。包括开云、开云棋牌、开云彩票、开云电竞、开云电子、全球各地赛事、动画直播、视频直播等服务。开云体育,开云体育官方,开云app下载,开云体育靠谱吗,开云官网,欢迎注册体验!其实,放在全球AI圈的大桌子上,大多数玩家都有个心照不宣的规矩:想做顶级大模型,就得像烧钱比赛一样,把美元按吨往算力炉子里倒。
OpenAI训练ChatGPT-4o动辄要7800万甚至1亿美元,这价格基本在给所有创业者划一道“门外勿近”的红线,你没资本,根本就没法玩。

结果,2025年的一个行业座谈会上,两组数字直接让全场哑火:一个是让人窒息的天价成本,另一个却只有——557.6万美元。
而DeepSeek-V3模型不仅没因为“便宜”而拉胯,在代码、数学、中文知识问答这些硬核项目上,居然正面赢了ChatGPT-4o。
行业还没反应过来,仅仅一个月后,DeepSeek又扔出更狠的——DeepSeek-R1,训练成本只要29.4万美元。

这个价格在硅谷还买不起套像样的房子,但它训练出来的模型却有着能和 OpenAI o1 正式版对着刚的推理能力。
行业里那种“烧钱换智能”的逻辑被狠狠拍在地上,像强行按头让人承认:不是钱越多越灵,就是你思路不对。
被拍在对面的,是一个40岁的广东湛江男人——梁文锋,他没有硅谷巨厂背景,没有几十亿美元融资,甚至没带什么商业戏码。

但他拿着一篇登上《自然》封面的论文和一种“算得清、花得狠”的精准主义,逼着整个行业重新思考:难道AI不是只能靠堆钱?难道还有另一条路?
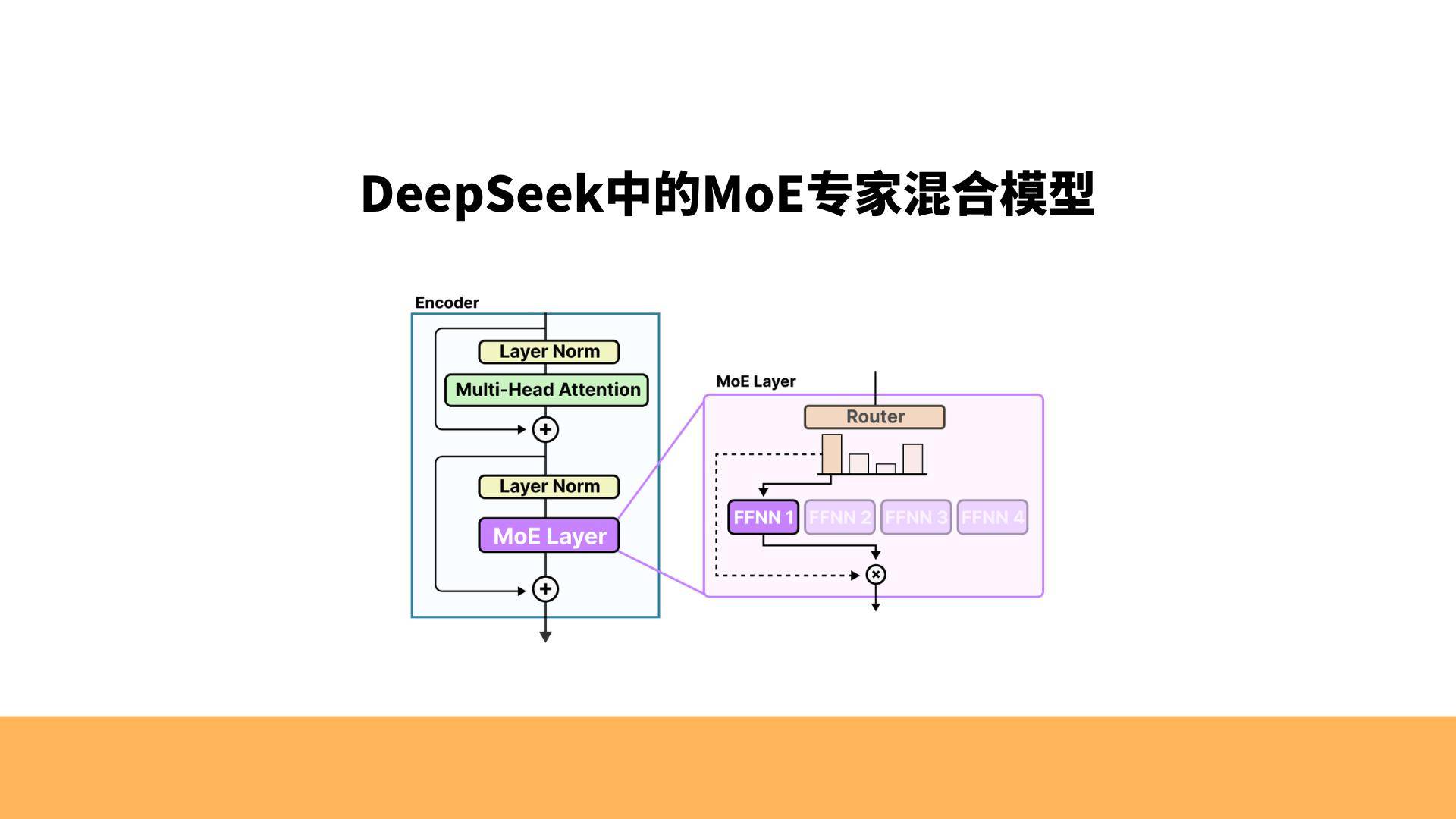
仔细看DeepSeek的做法就会发现,它不是砍成本,传统大模型喜欢“全网吞食”,把海量杂乱无章的信息一口气倒进模型里慢炖。
DeepSeek的想法更像是做菜时先挑干净:先把数据筛掉垃圾,只留对模型真正有意义的部分;先分类,再提炼,再压缩,像把食材里的水分挤干净,让模型吃进去的每一口都是营养。

这套“精准喂养”的逻辑,也解释了为什么DeepSeek团队只有一百多人却能干掉拥有一千多名工程师的大公司——不是人多就强,而是方向对了才强。
这一切的铺垫,本质上都源自梁文锋早年的“算得清”,他不是突然想做AI,而是从金融高频交易时代就开始把“效率”当成信仰。
2016年,当同行们还盯着K线图,他已经因为算力瓶颈,一口气砸2亿、搞1100块GPU建“萤火一号”。

所以2023年DeepSeek成立时,它根本不是新业务,而是一支摸爬滚打七年的队伍终于找到最大舞台。
如果按照商业世界的正常逻辑,DeepSeek的核心训练方法——尤其是那种让成本压到全行业脚底下的技术,应该被当成最高级别机密锁起来,连公司员工都未必能看全版本。
但梁文锋偏不走这条“常识之路”,2025年9月,他和团队把R1模型训练方法写成论文,不仅送审,还直接登上《自然》封面。

要知道,在这之前,行业里几乎所有大模型都拒绝同行评审,因为一旦接受评审,就意味着你要把那一大堆“神秘黑箱”摊在光天化日下。
结果DeepSeek不仅摊出来了,还让《自然》罕见地发评论说:“这一空白终于被DeepSeek打破。”这句话等于宣布:AI界几十年的“黑箱传统”被一个中国团队终结了。
更夸张的是,他不仅公开论文,还把R1的训练技术、全部流程、以及蒸馏后的6个小模型全部开源给社区。
这种做法用商学院的标准看简直是“裸奔式的自我拆护城河”。别人会说:你是不是疯了?好不容易做出大突破,为什么不把它锁起来赚钱?
可梁文锋的逻辑很简单:技术不是靠藏才能赢,而是靠生态越大,大家一起做得越快。
所以他才说那句人们反复引用的淡定小句:“如果要找商业理由,可能是划不来的。”但市场不按“商学院教科书”来反应。

模型上线后,开发者疯抢、同行围观,2025年9月下载量已经破1090万,全世界开发者的态度非常直接:好用就要,开源更要。
这种路数让人意识到:AI不是只能靠大资本跑,而是可以靠“生态势能”跑——你越公开,别人越愿意帮你进化。
更深一层来看,梁文锋的“开放”不是理想主义,而是技术逻辑,他深知,模型能力最终不是比谁藏得严,而是谁吸收的外部贡献更多。

开源不是送福利,而是自我强化,这种打法,在中国科技领域很罕见,也因此格外亮眼。
雷军在2025年两会上说,小米五年砸了1050亿研发、未来五年继续砸2000亿,这是真正的大规模“重兵集团军打法”。

两者并不矛盾,反而构成中国科技创新的双轨结构:一条是重投入、重产业链的正面推进;另一条是靠聪明、靠极致效率打敌人软肋的奇袭。
正因为有这两种力量,中国的科技叙事才变得厚度更足,而随着DeepSeek模型引爆全球,资本市场给出了最直接的反馈:公司估值冲上万亿,梁文锋个人资产数字不断刷新榜单。
但他本人倒是比谁都冷静,他很清楚,用户的月活数据可能在热度退去后自然回落——比如2025年9月的数据相较2月峰值有所下降。

但他反而把这看作健康信号,因为一个产品只有从“网红期”进入“基建期”,它才能变得稳定、长久。
DeepSeek带来的最大变化,并非是“省了多少钱”,也不是“模型性能有多牛”,而是它让世界第一次看到:原来AI行业几十年来遵守的那套“堆资源才能赢”的定律可以被彻底推翻。

这种推翻不是噱头,而是证明了一件事,AI的未来掌握在那些真正理解“效率、结构、数据质量、算法逻辑”的团队手里,而不是掌握在银行账户最厚的人手里。
这对全球科技生态是一次重新洗牌,更巧的是,在这些AI事件之外,中国科研的另一条长线也在同一时间爆发。
比如杜梦然团队乘“奋斗者”号潜入9000多米深渊,发现了地球最深的化能自养生态系统,也成功入选《自然》2025年度十大人物之一。

这些故事组合在一起发出的信号很清晰:中国科技不再靠模仿、靠堆料,而是走向原创突破、系统创新时代。
梁文锋说自己只是“不小心成了一条鲶鱼”。但这条鲶鱼搅动的,绝不仅仅是AI行业的小池塘,而是全球科技竞争框架。
那篇登上《自然》封面的训练方案,用区区29.4万美元,证明了一个全世界都不敢想的可能性:创新的火种从来不需要点燃整片森林。
只要方法对、逻辑对、思路对,哪怕你的资源只有对手的十分之一、百分之一,你仍然可以敲开通往未来的大门,并且走得更稳、更远。
这种思维方式,将继续深刻影响下一轮全球科技竞赛的方向,也为中国科技下一步的突破埋下伏笔。返回搜狐,查看更多
